
Télécharger le fichier suivant : encodage.txt
Pour connaître l'encodage d'un fichier :
pi@raspberry:~ $ file -i nom_du_fichier nom_du_fichier: text/plain; charset=iso-8859-1
On peut aussi utiliser chardet, un utilitaire qui permet de détecter l'encodage lorsque `file -i` ne retourne rien.
Pour installer [chardet](http://chardet.github.io/) :
pi@raspberry:~ $ pip install chardet
Pour l'utiliser
pi@raspberry:~ $ chardet nom_du_fichier
Après avoir téléchargé le fichier encodage.txt, trouver son encodage.
On peut aussi convertir un fichier sans passer par un éditeur. C’est par exemple
la fonction d’iconv, programme en ligne de commande disponible
sur les unixoïdes.
Pour convertir un fichier texte (ici NK.tex) d'un encodage mac vers un encodage UTF-8, on peut utiliser la ligne de commande suivante :
pi@raspberry:~ $ iconv -f macintosh -t UTF-8 NK.tex -o NK2.tex
On peut aussi voir l'encodage caractère par caractère avec la fonction hexdrump, on pourra utiliser la ligne de commande suivante :
pi@raspberry:~ $ hexdump -C nom_du_fichier 00000000 ff fe 64 00 e9 00 6a 00 e0 00 0a 00 |..d...j.....|
encodage.txt.
On va maintenant voir comment gérer l’encodage de nos fichiers. Tout éditeur de texte digne de ce nom permet de le faire de façon précise… mais commençons par le Bloc-Notes de Windows. Ouvrons le Bloc-Notes, tapons un peu de texte avec des accents, puis enregistrons.
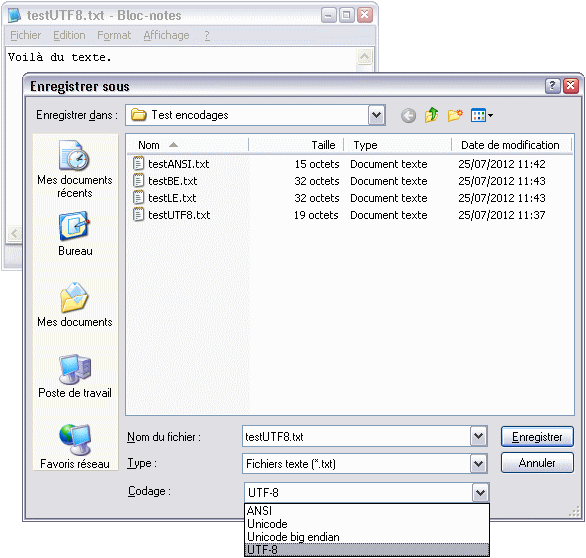
Boîte de dialogue d’enregistrement du Bloc-Notes
Le Bloc-Notes permet au premier enregistrement de choisir l’encodage du fichier. Le choix est assez limité cependant : « ANSI » (Windows-1252), « Unicode » (UTF-16LE), « Unicode big endian » (UTF-16BE), ou UTF-8. Comme exercice, vous pouvez vous amuser à vérifier que les tailles des fichiers affichées sur ma capture sont correctes, sachant que mon texte comporte quinze caractères et que le Bloc-Notes ajoute automatiquement une BOM pour tous les encodages Unicode (qui fait deux octets en UTF-16 et trois octets en UTF-8).
Le Bloc-Notes est vraiment très limité. Ainsi on ne peut pas choisir le latin-9 par exemple. De plus, rien n’indique l’encodage du fichier sur lequel on travaille, et on ne peut pas en changer après coup.
Si vous programmez, vous utilisez certainement un éditeur plus avancé. Comme les navigateurs web, la plupart incluent un menu pour passer d’un encodage à un autre. Toujours sous Windows, voici l’exemple de Notepad++ (ici j’ai rouvert les fichiers que je viens de créer avec le Bloc-Notes) :
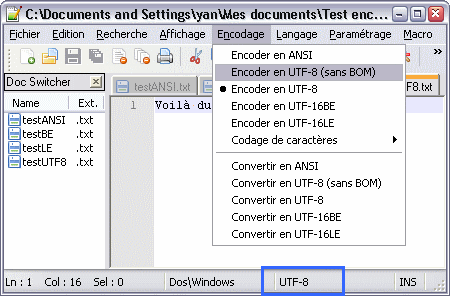
Le menu des encodages dans Notepad++
Première remarque, Notepad++ détecte automatiquement l’encodage et l’indique dans la barre de statut (en bas, encadré en bleu). C’est déjà mieux. En passant, remarquons la mention « Dos\Windows ». Elle indique le style utilisé pour les fins de ligne. On avait vu qu’il existait plusieurs conventions, selon les OS. Ici, notre fichier utilise le style Windows, c’est-à-dire CRLF.
Ensuite, le menu « Encodage » permet de changer en direct l’encodage utilisé. Comme dans les navigateurs web, les options « Encoder en xxx » changent l’interprétation des octets existants ; en plus, elles déterminent le codage des caractères nouvellement insérés. Pour modifier l’encodage d’un fichier, il ne faut pas cliquer sur « Encoder en xxx », car cela n’adapte pas le contenu existant ; pour ça, il faut faire « Convertir en xxx ».
Enfin, on a quand même plus de choix que dans le Bloc-Notes !
Après cet aperçu, faites un tour dans la configuration de votre éditeur. Il y a certainement des options qui nous intéressent.
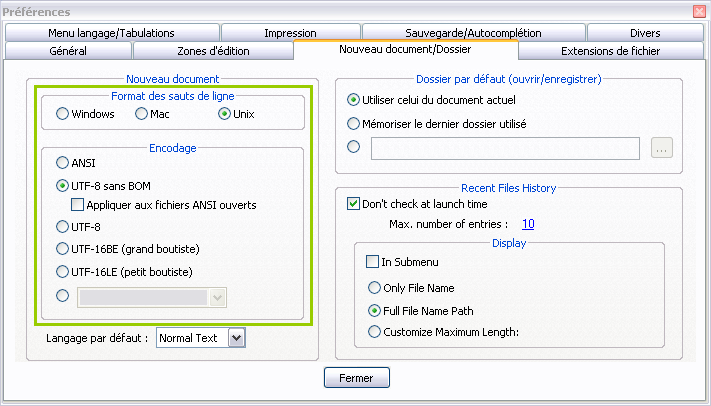
Fenêtre de configuration de Notepad++
Ici, j’ai encadré la partie intéressante en vert. On peut choisir l’encodage (et le format des fins de ligne) qui sera utilisé par défaut lors de la création d’un nouveau fichier.
Remarquons qu’il y a deux encodages UTF-8. L’une porte la mention « (sans BOM) », ce qui signifie que l’autre est un « UTF-8 avec BOM ». On a déjà parlé de la BOM, ce caractère Unicode spécial placé tout au début d’un fichier pour en indiquer le boutisme. Cette technique est utilisée pour l’UTF-16 et l’UTF-32. En revanche, elle est inutile en UTF-8 puisqu’on n’a pas de problème de boutisme. Pire, elle peut rendre des fichiers invalides pour certains programmes. C’est par exemple le cas des pages web, comme on verra plus tard. Pourtant, certains éditeurs dont le fameux Bloc-Notes la rajoutent automatiquement même en UTF-8, car ça les aide à détecter l’encodage du fichier. C’est une pratique déconseillée. Dans votre éditeur favori, choisissez toujours la version sans BOM si vous avez le choix.
Ici, nettoyons notre fichier de cette hérésie avec Notepad++. Pour ça, on fait simplement « Convertir en UTF-8 (sans BOM) » et on enregistre. Dans les paramètres, on choisit aussi l’UTF-8 sans BOM par défaut.